
这就如同协调工程车辆奔赴工地,传统的宽大工程车固然装载量(精度)较大,但在有限的道路宽度上却易造成拥塞。而小型化工程车虽然装载量小,但其更高的通行效率却反而会带来整体效能提升。
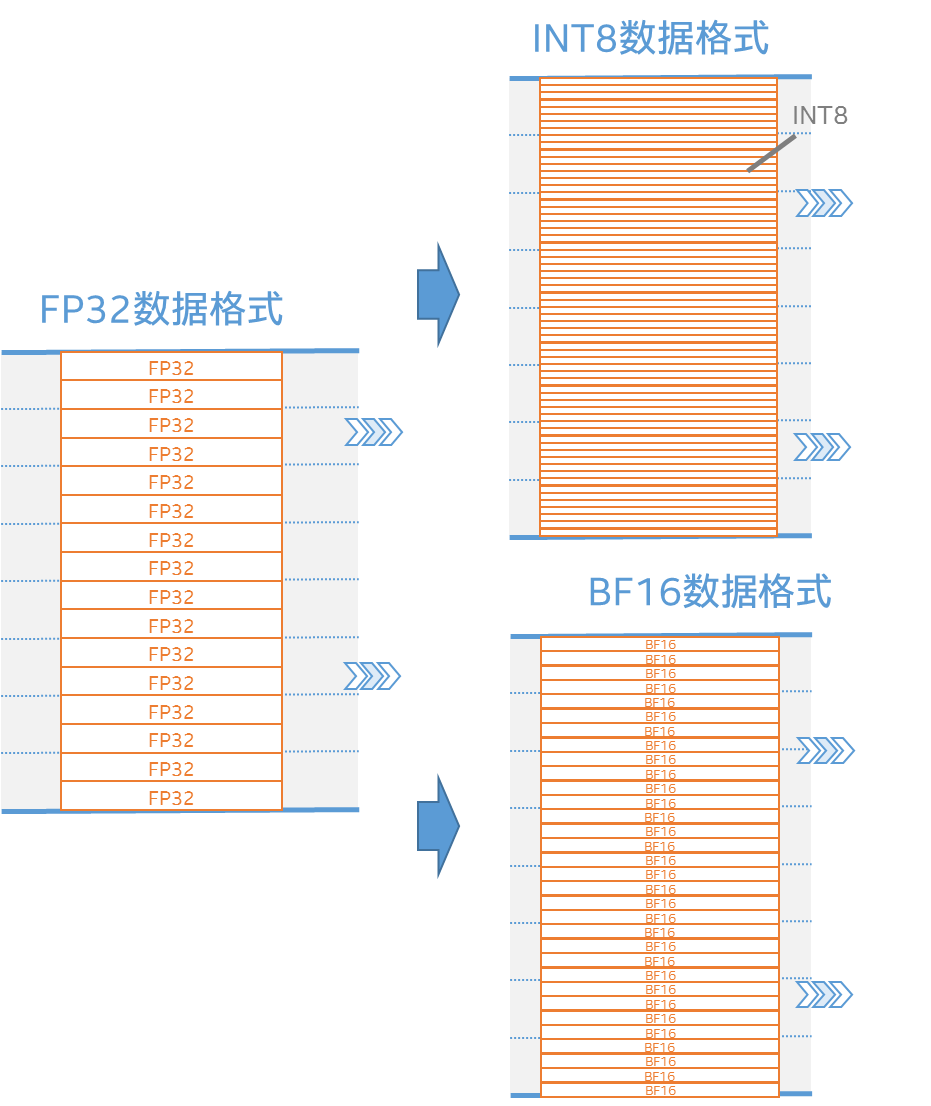
从图一可以看出,当数据格式由FP32转为8位整数(INT8)或16位浮点数(BF16)时,内存可以移动更多的数据量,进而更大化地利用计算资源。

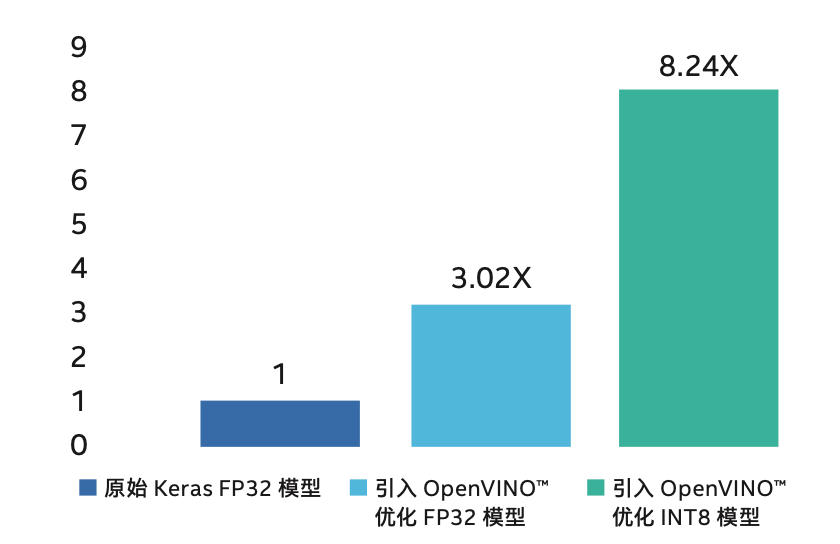
让我们来看看更接地气的实践场景。以医疗影像分析为例,如图三所示,汇医慧影在乳腺癌影像分析场景中引入了集成有英特尔® 深度学习加速技术的第二代英特尔® 至强® 可扩展处理器,配合 OpenVINO™ 工具套件,在对检测模型进行了INT8转换和优化后,推理速度较原始方案提升高达 8.24 倍,且精确度损失不到 0.17%[5]。
[2] 相关研究例如:
Vanhoucke, et al. (2011):
https://research.google.com/pubs/pub37631.html;
Hwang, et al. (2014):
http://ieeexplore.ieee.org/abstract/document/6986082/;
Courbariaux, et al. (2015):
https://arxiv.org/abs/1412.7024;
Koster, et al.(2017):
https://arxiv.org/abs/1711.02213;
Kim and Smaragdis (2016):
https://arxiv.org/abs/1601.06071。
[3] 数据援引自:
https://www.intel.com/content/www/us/en/artificial-intelligence/posts/lowering-numerical-precision-increase-deep-learning-performance.html
[4] 测试配置如下:
测试组配置:单节点,4 个安装在英特尔参考平台 (Cooper City) 的第三代智能英特尔® 至强® 可扩展 8380H 处理器(预生产 28C,250W),总内存 384 GB(24 个插槽/16 GB/3200),ucode 0x700001b,超线程开启,睿频开启,带有 Ubuntu* 20.04 LTS,Linux* 5.4.0-26,28,29-generic,英特尔 800 GB 固态盘 OS 驱动器,ResNet-50 v 1.5 吞吐量,https://github.com/Intel-tensorflow/tensorflow -b bf16/base,commit #828738642760358b388d8f615ded0c213f10c9 9a,Modelzoo:https://github.com/IntelAI/models/ -b v1.6.1,Imagenet 数据集,oneAPI 深度神经网络库 (oneDNN) 1.4,BF16,BS=512,英特尔于 2020 年 5 月 18 日进行测试。 基准组配置:英特尔参考平台 (Lightning Ridge) 上的 1 个节点、4 个英特尔® 至强® Platinum 8280 处理器,总内存 768 GB(24 个插槽/32 GB/2933),ucode 0x4002f00,超线程开启,睿频开启,Ubuntu* 20.04 LTS,Linux* 5.4.0-26,28,29-generic,英特尔 800 GB 固态盘 OS 驱动器,ResNet-50 v 1.5 吞吐量,https://github.com/Intel-tensorflow/tensorflow -b bf16/base,commit #828738642760358b388d8f615ded0c213f10c99a,Modelzoo:https://github.com/IntelAI/models/ -b v1.6.1,Imagenet 数据集,oneAPI 深度神经网络资料库 (oneDNN) 1.4,FP32,BS=512,英特尔于 2020 年 5 月 18 日进行测试。
[5] 案例链接:
https://www.intel.cn/content/www/cn/zh/analytics/artificial-intelligence/accelerated-ai-on-xeon.html
[6] 详情请见:
https://www.intel.cn/content/www/cn/zh/artificial-intelligence/posts/intel-facebook-boost-bfloat16.html
©英特尔公司版权所有。
* 文中涉及的其它名称及商标属于各自所有者资产。
